How metadata supercharges analytics in Parse.ly
Parse.ly tracks a number of directly-measured metrics from websites, such as views, visitors, time, and shares.
In addition to this, Parse.ly tracks “page metadata” using one of several content management system (CMS) integrations. In fact, page metadata is Parse.ly’s “secret weapon” that supercharges the way its analytics dashboard works, so that all of the data is engaging to day-to-day users who may not normally log into analytics tools.
This post will cover exactly how metadata works in the Parse.ly system. We’ll start at how metadata is integrated; how that data flows into our dashboard and API; and how Parse.ly handles changes to metadata over time. The last section of the post goes into advanced use cases of metadata.
Integrating page metadata into Parse.ly
Parse.ly has a number of metadata integration options, which include:
- a simple JSON tag included on every page, which is technically implemented using two web standards: JSON-LD, for embedding JSON on HTML pages, and schema.org/NewsArticle. A benefit of this format is that Google and other services use it to recognize news content.
- a small set of META tags on every page, each of which have the
parsely-prefix, and which populate various bits of metadata in a controlled manner specifically for Parse.ly’s tools. - tracked metadata for sites with limited CMS customization options. Sometimes sites rely upon a dynamic tag managers or include embedded video content which is not actually “crawlable”. In these cases, Parse.ly’s JavaScript tracker is modified to send metadata about the page with the first
pagevieworvideostartevent triggered on any page or video load. This means that you don’t need to include any Parse.ly metadata in your HTML, as you do with the other formats.
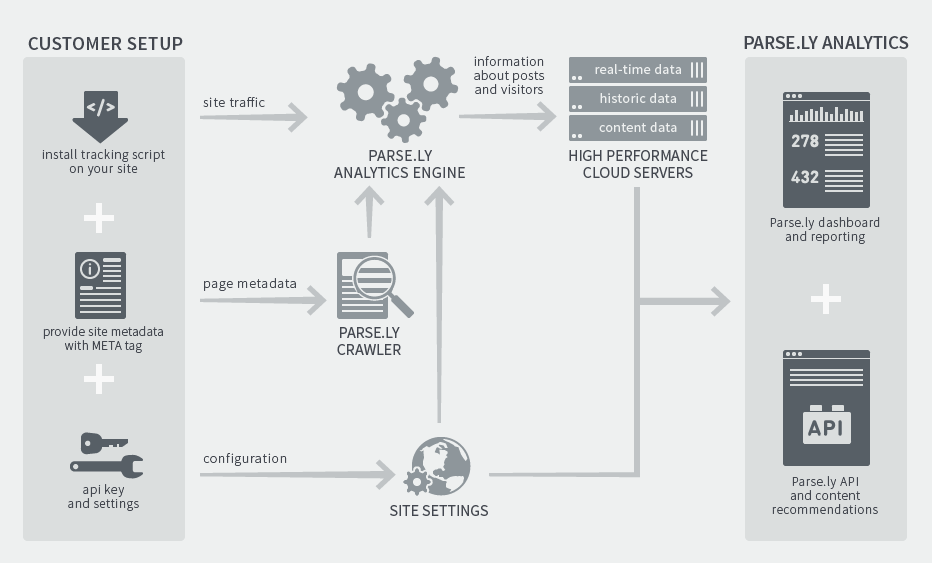
Once our tracking code is installed and page metadata is exposed (or sent), Parse.ly joins all this data together to power real-time and historic views in its dashboard and APIs. At a high-level, this is how the overall architecture looks:

How metadata looks inside Parse.ly
An example of the kind of metadata collected by one of these integration options includes:
title, aka “headline” or “page title”authors, aka “creators” or “byline”section, aka “category” or “genre”tags, aka “keywords”, “content types”, “content groups”, or “topics”pub_date, aka “publish time” or “posted date”
Here is an example of how a “post” looks inside the Parse.ly analytics dashboard, thanks to all of this metadata:

Every single piece of metadata here — the author, section, tag, etc. — links to a detail page describing the analytics for all the content that matches that given field. For example, clicking “Clare Carr” in this post would show us a detail screen with all of Clare’s posts across the selected time period.
In the case of the first two integration options described above, Parse.ly actually sends a web crawler (similar to Google’s) to your site, and downloads the metadata about the piece of content once (or several times, if the content changes), and then joins that metadata with each event — such as a page view or time spent tracking event — automatically.
In the case of the third integration option (“tracked metadata”), the page metadata is sent along with the pageview event. Thus, if a page gets 100,000 pageviews, Parse.ly will receive 100,000 copies of the page metadata for that page. This is not ideal in terms of impact on user experience and data storage, but it benefits from a certain simplicity that when the metadata changes, Parse.ly will receive “new” metadata instantly (at least, so long as the page is active with events).
Customers should also be aware that certain pieces of metadata can only be collected by Parse.ly’s crawler, and are collected automatically (not requiring any specific tagging of the page). These include full_content and full_content_word_count. The full_content field can often contain hundreds, or thousands, or even tens of thousands of words of content. Therefore, it’s not practical to send this information, on a repeated basis, with each event; a periodic crawl schedule is more sensible. These fields are useful to power Parse.ly’s recommendation engine, which provides automatic content recommendations based on contextual relevance to the content within each page. It also powers our dashboard search functionality. For example, here’s a dashboard search looking for all the posts the Parse.ly team has published about our “data pipeline” product:

One quick note about our web crawling system: you may be worried about additional load that the crawler might put on your server. This is generally not a concern. The crawler takes a number of steps, described here, to be polite to the servers it crawls.
How Parse.ly makes use of metadata
Collecting metadata from your sites/apps allows Parse.ly to automatically group your analytics data in an organized fashion.
In particular, it powers automatic analytics breakouts by page, post/video, author, section, and tag in the Parse.ly Dashboard. It also allows for arbitrary filtering by any of these, and also by publication date.

Similarly, metadata allows for easy calls to the Parse.ly API that pull back analytics data by page, post/video, author, section, and tag, summarized over any time period and returned in HTTP/JSON /analytics endpoints. The metadata is also used for the benefit of making better content recommendations for users of our /related endpoint.
Finally, metadata allows for rich raw data analysis in Parse.ly’s Data Pipeline. The information about the page, article/video, author, section, and tag is automatically joined to every raw event Parse.ly delivers to your analyst or BI team, so that it can be used as part of grouping, filtering, and/or audience segmentation. You can see the documentation on this in our metadata enrichments in the Parse.ly event schema.
Understanding “recrawls” and “rebuilds”
Although metadata changes much less frequently than visitor and page events, each page’s metadata does, occasionally, change. Some examples include:
- changing a headline, either as a result of an A/B test; to optimize for search or social; or to include new information about a story
- re-labeling an author, section, or tag, either correcting a mistake in your content management system, or adding a new tag as a result of a new analysis you want to perform
- changing body text, for example for “live blogs” or posts with content that evolves over time
- removing a post, for example when it’s discovered that the content was put online in error, or to redirect users to a different piece of content
To deal with the reality of changing metadata, Parse.ly employs several strategies:
Automatic recrawls
Parse.ly’s crawler will re-visit an active URL once an hour for the first 24-hours after publication in order to discover changes to metadata; when changes are found, the “last good crawl” wins and overwrites prior versions.
Automatic rebuilds
Crawl data may change and Parse.ly needs to back-populate the changes to prior event records that might have been recorded with incorrect metadata. For example, imagine a post is published with the wrong author for the first 24 hours of its life, but then the author field is corrected for the last 12 hours of its life.
Since Parse.ly reports data in real-time, the first 24 hours will be recorded with the original (wrong) author name, as the data arrives. Once the name is corrected, however, Parse.ly reports on it correctly moving forward. However, it also needs to “rewrite” that history to point to the correct author.
In other words, Parse.ly is designed to reflect the most up-to-date version of a page’s metadata in its historical record. To do this, Parse.ly employs automatic rebuilds which run once a day across all of our data, and always use the latest version of metadata for any given site or page. This ensures the strongest possible data quality, allowing the system to course-correct when metadata changes need to be applied retroactively.
Note that if you use “tracked metadata” (aka “in-pixel metadata”), rebuilds will not change the metadata associated with each pageview event, as the metadata is part of the event from the beginning. That said, the Parse.ly dashboard will always show the most recent metadata available for a page for the selected time range.
Manual recrawls and rebuilds
Parse.ly recognizes that occasionally, this metadata refresh strategy will fail systemically — for example, when a site does a total redesign and changes every page, URL, tag, etc. across the board. Some sites might do these changes for 1,000’s or even tens of 1,000’s posts/videos at once. In most analytics tools, these events are devastating for analytics records, which are now permanently ruined, stale, or subtly incorrect.
However, Parse.ly’s much more flexible analytics engine can be instructed by our support team to run a “manual recrawl” across the site to expedite a refresh to all metadata. Our team can also run a “manual rebuild”, which associates all your historical traffic stats with the updated metadata. This service is so valuable that we provide it to our customers as part of a premium support package. To our knowledge, no other analytics tool on the market does this.
Checking metadata with the validator
To make it easier for users to understand whether metadata is integrated correctly, and to see the Parse.ly crawler’s view of content on a given page, we have built a public validator tool. Paste any URL that is integrated with Parse.ly tracking and metadata (using either option #1, a JSON-LD tag, or option #2, repeated META tags, described at the start of this article), and we will show you all the extracted values.

Note that if you use “tracked metadata” (aka “in-pixel metadata”), this validator tool cannot check the results. For that, we suggest you inspect the PARSELY.lastRequest object in a JavaScript console open on your page, e.g. using Chrome Inspector. You can also use the JavaScript console to confirm that your site is sending us pageviews correctly.
Informing Parse.ly of changed pages
Parse.ly describes its web crawler publicly in the technical documentation. To issue a recrawl request for any URL that is integrated with Parse.ly metadata (using either option #1, json-ld, or option #2, parsely-page, described at the start of this article), simply issue an HTTP request against our ping_crawl API, as described here. If you’ve purchased API access, you can also submit a URL for recrawl simply by pasting it into the “Recrawl post” field on https://dash.parsely.com/*example.com*/settings/api. You’d still want to contact your account manager to initiate a rebuild if you’d like historical stats for the URL to be associated with the updated metadata.
Note that if you use “tracked metadata” (aka “in-pixel metadata”), this ping_crawl endpoint will not actually issue a crawl request to the page. Instead, our pipeline will expect to receive a new pageview event from a recently-changed page with new metadata, because the pageview event itself is the only canonical source of the metadata. In other words, our crawler has no work to do.
This means that for old (archival) content that is no longer receiving traffic, the crawl records will not change until they receive at least a single pageview event. Thankfully, most public online content receives at least a pageview per week due to bots like the Google crawler, so this might just happen automatically to your archive over time.
Metadata supercharges analytics!
On the Parse.ly team, we have done a lot of content analytics deployments over the years. We now work with hundreds of companies and track thousands of premium sites, each one integrated using the data flow described above.
What we have learned over the years is that metadata supercharges analytics! It makes reports instantly actionable, comprehensible and engaging. Metadata automatically organizes all your analytics into neat and flexible reports, which are automatically linked to one another, allowing simple drill-down explorations.
Feel free to reach out to us at https://parse.ly/help if you have further questions about metadata, or how Parse.ly might work better for your site.
Appendix: metadata views in the Data Pipeline
Note: in this appendix, advanced Parse.ly users of our Data Pipeline can learn how to make use of our page metadata when working with raw Parse.ly event data. This requires a little knowledge of our raw data schema and SQL.
If your company makes use of Parse.ly’s Data Pipeline, managing metadata changes becomes a responsibility of your analyst or data science team.
Parse.ly will deliver 100% of its raw, unsampled events in its real-time stream (Amazon Kinesis), and will also deliver a full archive of all that data to its elastic bulk archive (Amazon S3). As described in the metadata enrichments, every pageview, videostart, and similar event will include the corresponding metadata attributes described above, joined to the event via the url_clean field.
To construct a table of all of your metadata for URLs that appeared with pageview events in your raw data store, use a SQL query like this:
SELECT
-- core identifying fields:
metadata_canonical_url,
url_clean,
ts_action,
-- some page metadata fields:
metadata_title,
metadata_section,
metadata_pub_date_tmsp,
FROM
parsely.rawdata
WHERE
-- must be a pageview event
action = 'pageview'
-- must have a canonical URL
AND metadata_canonical_url IS NOT NULL
The results of this query could be saved as a view, and now you’d have a table of url_clean values with their corresponding metadata_title, metadata_section, metadata_pub_date_tmsp, etc. columns. To save some space, I didn’t select the full set of metadata fields here.
What happens if metadata changes? In these cases, your new events will receive the latest values of the metadata, whereas your old events will have old versions of the metadata associated with them.
How do you implement your own “recrawl” or “rebuild” process atop the Parse.ly Data Pipeline? This will depend on your technical architecture, and which particular SQL or analysis engine you use over your raw data. But for the rest of this article, we will assume you are keeping every event as a raw record, and that you are using a high-performance cloud SQL engine (such as Amazon Redshift or Google BigQuery) which can materialize “views” over the raw data efficiently. This will give you a logical table of “metadata-per-url as of right now”.
Once you have a SQL view of the “all metadata” in your event stream, as we described above, you can use that metadata as the “canonical” metadata for any given url_clean column value. Here, we will use a sub-select and the SQL ROW_NUMBER() and PARTITION OVER facilities (aka “window functions”) to easily identify the freshest metadata entry. This will allow us to get a live view of the “freshest metadata” for any given set of events.
SELECT * FROM (
-- we select all columns, since the sub-select
-- will filter the number of columns down
SELECT
-- this will be 1 for the freshest records
ROW_NUMBER() OVER(
PARTITION BY metadata_canonical_url
ORDER BY ts_action DESC)
as freshness,
metadata_canonical_url,
url_clean,
ts_action,
metadata_title,
metadata_section,
metadata_pub_date_tmsp,
FROM parsely.rawdata
WHERE action = 'pageview'
AND metadata_canonical_url IS NOT NULL
)
-- filter to the freshest crawl records
WHERE freshness = 1
For convenicence in your database, you’ll probably want to save a query like the above as a view. In my case, I saved it as a view called view_metadata_recent.
If your metadata changes, you still need to let Parse.ly know about it (so that it can do a recrawl), but once a recrawl happens, you’ll receive the new metadata in the more recent events delivered by the Data Pipeline. Since you’ll already have a SQL view with the latest version of that metadata, you can simply “join it back” to any old analytics records in your warehouse to do a “dynamic rebuild”. You could even save this “dynamically rebuilt” data as a new view of your event stream.
Here’s an example of how that might work:
SELECT
m.metadata_section as section,
SUM(CASE
WHEN e.action = 'pageview'
THEN 1 ELSE 0 END) as num_views,
SUM(CASE
WHEN e.action = 'heartbeat'
THEN e.engaged_time_inc ELSE 0 END) as num_seconds,
COUNT(DISTINCT m.metadata_canonical_url) as num_posts
FROM parsely.rawdata as e
JOIN parsely.view_metadata_recent as m
ON e.url_clean = m.url_clean
WHERE m.metadata_section <> ""
GROUP BY section
ORDER BY num_views DESC
LIMIT 500
In this example, the saved view from earlier, view_metadata_recent, is being joined to the event stream using the url_clean column. This is basically back-populating the “freshest” metadata to all event records. Finally, a simple aggregate is calculated: we are grouping all content by section, then calculating the num_views (the total number of pageviews), num_seconds (the total engaged time, in seconds), and the num_posts (the number of distinct canonical URLs; that is, the number of unique pieces of content). Here is an example of how this custom report looks as a resulting SQL table:

Now filtering those events by specific audience segments (e.g. new vs returning visitors), or by specific device (mobile vs tablet), or by specific metadata attribute (tag, author, or publication time) is just a simple WHERE clause away.
Feel free to reach out to us at https://parse.ly/help if you have further questions about using metadata with the Data Pipeline, or how Parse.ly might work better for your site.