Apache Storm: The Big Reference
Apache Storm is a free and open source project that is heavily used here at Parse.ly, as well as at other major real-time data processing projects such as Twitter, Pinterest, Spotify, and Wikipedia.
In the last year, a flurry of digital documentation has been released about Storm, as the project gained traction in the commercial community. The project also entered Apache as a formal “incubating” project.
So, what is Apache Storm?
Apache Storm is a free and open source distributed realtime computation system. Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Storm is simple, can be used with any programming language, and is a lot of fun to use! Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more.
Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate. Storm integrates with the queueing and database technologies you already use. A Storm topology consumes streams of data and processes those streams in arbitrarily complex ways, repartitioning the streams between each stage of the computation however needed.
–Apache Storm project page
Storm is also a thriving open source project — over 9,000 stars on Github, regular releases and improvements, a growing ecosystem of connectors and plugins, and many top companies relying upon it as a core data processing technology.
This post will provide a starting point for doing a deeper dive on Storm, by reviewing some of the print books, e-books, online resources, videos, and presentations that are currently available.
It will start with a discussion of The Lambda Architecture, a design pattern that underpins most Storm-based systems. We will discuss this architecture in the context of the recently-completed book by Nathan Marz, the creator of Storm.
From there, we were move into Storm internals and operation, along the way reviewing two other Storm-focused books that cover a wide spectrum of Storm use cases.
What is the Lambda Architecture?
At its core, the Lambda Architecutre is nothing more than a data processing pattern that is born out of a realization that large-scale data systems would be ideally served if they could re-compute the world at any time.
The term “lambda” in the name refers to a re-computation function, that is, the simple realization underpinning the architecture is that all derived calculations in a data system can be expressed as a re-computation function over all of your data.
If you are managing a system with terabytes or petabytes of immutable facts collected from your customers, users, or partners, you would like to change your interpretation of those facts at any time, and re-run all of your analyses at will.
Thanks to large-scale batch processing systems like Apache Hadoop’s Map/Reduce, this isn’t as untenable as it once seemed. We now have cloud computing resources that can be spun up at will, and frameworks will parallelize our computations over a cluster of machines. However, even though this is possible, the latencies on these parallelized batch computations are on the order of many minutes or even hours.
Since modern software requirements also require answers to questions about recent data, you need to provide real-time answers, as well. These answers should come from the same system that provides historical calculations and performs re-computations in light of a changing data processing codebase.
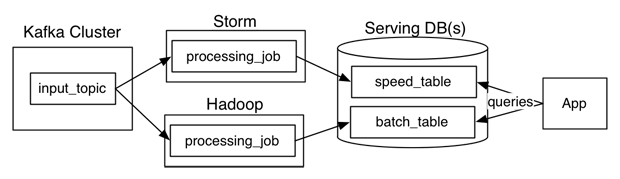
This is what the Lambda Architecture seeks to solve. It says given these requirements, you should divide your system into three distinct layers:
- the “batch” layer, which computes functions over all data with high latency and rewrites immutable fact transformations into your data stores (e.g. via Hadoop)
- the “speed” layer, which computes functions over recent data with low latency and mutates your real-time data stores directly (e.g. via Storm)
- the “serving” layer, which abstracts over those two to provide unified answers to real-time and historical questions (e.g. your own query layer).
The proposed benefit of the Lambda Architecture is to achieve the “best of both worlds” data architecture, albeit with a major trade-off: the need to maintain two synchronized codebases for each of the batch and speed layers. This tradeoff will be discussed near the end of this article.
The ideas behind this architecture cemented in Nathan Marz’s mind in 2011, in his blog post, “How to beat the CAP theorem”.
Since the realtime layer only compensates for the last few hours of data, everything the realtime layer computes is eventually overridden by the batch layer. So if you make a mistake or something goes wrong in the realtime layer, the batch layer will correct it. […] In the batch layer, you only have to think about data and functions on that data. The batch layer is really simple to reason about. In the realtime layer, on the other hand, you have to use incremental algorithms and extremely complex NoSQL databases. Isolating all that complexity into the realtime layer makes a huge difference in making robust, reliable systems. Additionally, the realtime layer doesn’t affect the human fault-tolerance of the system. The append-only immutable dataset in the batch layer is still the core of the system, so any mistake can be recovered from just like before.
Marz developed this concept further in his book, Big Data, which we shall discuss now.
Big Data, the book

Marz is a prolific open source contributor. He created Storm while still working at BackType, before it was acquired by Twitter. He also developed several other data processing utilities in the Java and Clojure communities, including Cascalog, ElephantDB, and dfs-datastores.
Big Data, the book is a mixture of theory and practice. It introduces The Lambda Architecture and some key principles behind it, such as “human fault tolerance” and “eventual accuracy”. It also walks through some of Marz’s favorite Java libraries and utilities for working with big data sets, such as Thrift, HDFS, Cassandra, and Kafka.
The context of the book is to build a fictional web analytics service called SuperWebAnalytics.com. By the end of the book, the service includes support for real-time and historical page view tracking, as well as some advanced analyses you might find in a service like Google Analytics, e.g. Bounce Rate analysis.
The batch layer is able to re-compute page view values across all URLs by using a master data set in HDFS and Cascalog queries. It’s able to calculate real-time page views on any URL by using real-time values updated in Cassandra. The connection to Storm? That only comes late in the book: it’s how the speed layer is implemented and how to the Cassandra ColumnFamilies are updated.
In this respect, the book serves as an interesting introduction to Storm, but is not really a detailed tutorial of Storm as a technology. This may be a surprise given that Storm is Marz’s most well-known open source project.
Despite this, the book does end with some advanced Storm concepts. The aforementioned Bounce Rate Analysis is actually accomplished using Storm’s newer Trident framework.
Trident is Storm’s “high-level abstraction” — similar to Pig or Cascading — for compiling Storm topologies from declarative data flows (the API uses a Java fluent interface). Despite personally being an advanced Storm practicioner for more than a year, this part even went a bit over my head. I think Trident is very cool, but it’s currently a little too Java-y for my taste, and ruins the simplicity of Storm for me, so I prefer not to use it. It also has limited support for multi-lang (non-Java) topologies currently.
Based on all this, I consider this book an “opinionated walk through the Java Big Data ecosystem, hosted by Storm’s creator, Nathan Marz.” It’s an engaging read for people deeply interested in how to do analytics at scale. If you were ever curious, “How might I implement a service like Google Analytics on my own?” this book offers one of the most compelling answers. It also raises a lot of architectural and design issues that are worth thinking about. But it’s not a Storm tutorial by any stretch, so reading the book will leave you with more questions than answers about Apache Storm.
Real-time Streams & Logs
So, let’s say you read Big Data, the book, and you are still at a loss for whether Storm is a good fit for your problems. This is a shameless plug, but at that moment, I’d recommend you consider watching the 45 minute presentation that I gave with a colleague at PyData 2014 Silicon Valley, entitled “Real-time Streams & Logs with Storm & Kafka”.
Here is an overview of that video:
A new generation of data processing platforms — which Parse.ly internally calls “stream architectures” — have converted data sources into streams of data that can be processed and analyzed in real-time. This has led to the development of various distributed real-time computation frameworks (e.g. Apache Storm) and high-performance data integration technologies (e.g. Apache Kafka).
In this video presentation, Andrew Montalenti (Parse.ly’s co-founder and CTO) and Keith Bourgoin (an early Parse.ly employee and its backend lead) gave an overview of what they have seen in the field, and how their team applied this knowledge to a backend re-implementation at Parse.ly. By re-orienting their data processing around an “immutable log” and rebuilding their backend architecture using a “formal computation graph”, they were able to deliver flexible queries, low latencies, and system-wide reliability to their large digital publisher client base.
In this presentation, we go into depth why we rewrote a (working) distributed system that used a traditional workers-and-queues architecture to use Apache Storm, instead. Since Parse.ly is a real-time web analytics system for digital publishers, we discovered a lot of the same lessons Marz discusses in his book.
It also is a less opinionated walkthrough than Big Data, the book, because it views Storm and Kafka as technologies that enable real-time stream and log processing for any programming language. In other words, it views them as infrastructure technology rather than as Java technology.
In fact, we use Storm and Kafka exclusively with Python, but I have met engineers who have built systems using Storm and Kafka with Ruby, Go, JavaScript, and even PHP. Unfortunately, most of the references for Storm out there make the assumption that you are a Java or Clojure programmer, making it seem like the technology is off-limits to other programmers. But this simply isn’t true. Similarly to Hadoop Streaming, Storm has support for shell-based processing that can integrate any programming language via its multi-lang protocol. It also recently added support for pluggable serialization in the multi-lang layer, which means that some day soon, these will likely be “just as fast” as the native Java option.
If video isn’t your thing, we also have slides and HTML notes available. And if you happen to use Python and are interested in Storm, our open source streamparse project has some of the best getting started docs available for using Storm and Python together.
Topologies and Ops with Storm Applied

Storm Applied (Amazon) is the first book on the market that provides a relatively complete, soup-to-nuts overview of Storm as a technology meant to be run in production. Whereas Big Data, the book, is a mixture of theory and practice with a discussion of Storm near the end, Storm Applied is all about Storm in practice, from the beginning to the end. It’s a more practical book for those who just want to get up-and-running with Storm without fully grokking its architectural underpinnings.
The book is not complete yet (currently at Manning Early Access v5) but has accumulated a lot of very useful and practical information, informed also by real-world experience running Storm clusters at The Ladders. You can read their recent blog post, “A Brewing Storm”, discussing Storm’s adoption at that company.
The authors, Sean T. Allen, Matt Jankowski and Peter Pathirana, work together at The Ladders and sought to create a comprehensive book on Storm for the community. The goals they lay out in the book’s foreword are well-achieved in the book already, even in this early draft form:
- Teach you about Storm and its concepts and terminology
- Teach you how to map problems from domains you might be familiar with onto Storm
- Teach you the in’s and out’s of maintaining Storm in a production environment
The book has some other interesting aspects. First, rather than using Storm with its most typical queuing technology, Apache Kafka, these authors integrated Storm into an existing queue-oriented system running with RabbitMQ. One of the authors implemented storm-rabbitmq, a Storm spout that makes it easy to feed data tuples into a Storm cluster from existing RabbitMQ infrastructure, and this plugin is discussed briefly in the book. I think this is interesting because likely, before you ever heard of Storm and Kafka, you were already doing worker-and-queue systems using RabbitMQ. It’s sort of the “default option” if you are doing queue-oriented processing with open source software. So, by reading about this, you might learn how to plug Storm into your existing data system without taking the existing system offline.
Second, rather than using Storm for a “sweet spot” use case — such as web analytics, market data, or streaming sensors — the authors actually used Storm to implement a rather run-of-the-mill order processing backend. The reason this is interesting is because it shows Storm’s generalizability — that it can be used reliably for real-time computations, both big and small, driven by fancy incremental streaming algorithms or ordinary business logic.
In a way, by choosing this simple and comprehensible problem domain (one which I’m sure most of its readers were forced to implement at one time or another), readers are able to see both the parallels and differences to the typical way of doing things in traditional workers-and-queues data processing systems they might have built in the past.
Storm Applied digs into topology design and production operations as additional key focus areas of the book. This is much appreciated, as these are often the thorniest issues you run into as you start to operate a Storm topology at scale. The chapters on topology design cover best practices and anti-patterns, complete with visualizations of how topologies are laid out, how data flows through them, and what happens in various common failure scenarios. The visualizations help the prose greatly and make it easy to walk through the various examples in one’s head.
They also go into the nitty gritty about how to make topologies reliable, how to handle message replays, and how to model bottlenecks. When the material shifts over to production operations, they provide detailed explanations of Storm configuration options, the Storm User Interface, and how to interpret internal logs, metrics, and values that appear there. This is information that is so useful, I feel it should eventually make its way into Storm’s official documentation, but right now their book is the only place to get it!
The book then shifts to tuning. Using accompanying visuals and explanations from the Storm UI, the authors explain how to identify bottlenecks iteratively, and how to improve topologies for latency and throughput. This includes implementing custom metrics atop Storm’s new metrics framework, which has very little public documentation available.
And, the authors are just getting started. I can’t wait for more chapters to come out — they have plans for ones on monitoring, debugging, Trident, and stateful stream processing. If you need a single book to get you started on running Storm for yourself, this is definitely the way to go.
The main downside to this book for me personally is that 100% of the examples are in Java. This isn’t a big deal for me, as I used to code Java regularly and can read Java comfortably. But some of the operational aspects of Storm change when you use multi-lang topologies, and some of the tuning advice simply doesn’t apply. I’d love for the authors to discuss multi-lang a little (and even include a streamparse example!) but I can understand that this may broaden the scope of the book a bit.
That said, ultimately, authors of books like these have to pick some language to work in for their code examples, and given that Storm is a JVM project, it’s natural that they would pick Java. So that’s not that big a criticism, and even without an advanced Java understanding, the examples are simple enough to follow along.
Advanced Integrations with Storm Blueprints

Storm Blueprints is written by P. Taylor Goetz, a Storm comitter and release manager for Apache who currently works at HortonWorks, and Brian O’Neill, the CTO at Health Market Science (HMS), a Storm user and open source contributor.
Big Data was a mix of theory and practice. Storm Applied delved into the nitty-gritty operational aspects of Storm. Storm Blueprints, by contrast, is more of a “cookbook with recipes” explanation of integrating Storm with various other technologies.
Its first two chapters cover Storm fundamentals using the infamous “distributed word count” example so common in tooling in this space. This covers some of the operational aspects of Storm, including configuration and node setup. But then it moves quickly into data processing patterns, starting with a discussion of Trident, Storm’s attempt to turn several micro-batch data processing patterns into a support library and domain-specific language. For illustration purposes, Trident is applied to a sensor data source.
From there, you are taken on a whirlwind tour of integrating Storm with several other important open source technologies: Kafka combines with XMPP to create a push architecture atop streams; Cassandra and Titan are used for graph processing over Twitter data; Druid is used for analyzing financial market data; Storm and Hadoop are combined in a mini Lambda Architecture for advertising analytics. Throughout all of this, several auxilliary tools are briefly introduced, including Zookeeper, Gremlin, Puppet, Vagrant, Whirr, HDFS, storm-yarn, etc.
If this sounds like a lot of ground to cover in a single book, it is. It is powerful to see Storm combined successfully with so many other technologies, along with the sample source code to prove it. This book serves as a reminder of just how much diversity there is in the current open source ecosystem around Hadoop and Storm, and how many production-ready and not-so-production-ready design patterns there are available to an engineer working in this space.
Since the book involved recipes and patterns while doing a survey across the ecosystem, I suffered from the expected bias from someone like me, who is an experienced practitioner. I’d have used Chef, not Puppet; I’d have stayed away from graph databases; I’d have focused on data stores like Cassandra and ElasticSearch more, which are more production-ready than some of the others discussed and fit more snugly into Storm’s architecture. But these are mostly nitpicks — overall, the book serves as an impressive jog across the Storm-related Big Data terrain, and shows that, as a platform, Storm can serve an important role in integrating disparate technologies scalably and predictably.
The Centrality of the Log
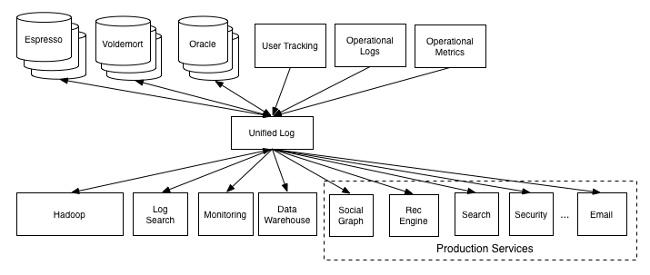
Jay Kreps, the creator of Apache Kafka, wrote an influential blog post awhile back on “The Log”. In it, he argues that “the log” may be the unifying concept of large-scale data integration projects.
The log is similar to the list of all credits and debits and bank processes; a table is all the current account balances. If you have a log of changes, you can apply these changes in order to create the table capturing the current state. This table will record the latest state for each key (as of a particular log time). There is a sense in which the log is the more fundamental data structure: in addition to creating the original table you can also transform it to create all kinds of derived tables.
Kreps goes on to discuss the importance of stream processing in this context. At LinkedIn, Kreps is not an Apache Storm user (they released their own stream processor with a similar design, called Samza). But, the concepts are the same:
Seen in this light, it is easy to have a different view of stream processing: it is just processing which includes a notion of time in the underlying data being processed and does not require a static snapshot of the data so it can produce output at a user-controlled frequency instead of waiting for the “end” of the data set to be reached. In this sense, stream processing is a generalization of batch processing, and, given the prevalence of real-time data, a very important generalization.
I recommend you read the entire article before going too deep on stream processing systems, because it has a very healthy perspective on its value.
Questioning the Lambda Architecture
Speaking of Kreps, he recently brought the entire discussion of The Lambda Architecture and stream processing full circle with his blog post for O’Reilly, “Questioning the Lambda Architecture”.
Kreps recognizes that the Lambda Architecture pointed the big data community toward some important problems, namely:
the Lambda Architecture emphasizes retaining the input data unchanged [… it models] data transformation as a series of materialized stages from an original input [… it] highlights the problem of reprocessing data.
Kreps says that “reprocessing is one of the key challenges of stream processing but is very often ignored”. He identifies reprocessing as a key challenge because “code will always change [… and] whenever the code changes, you will need to recompute your output to see the effect of the change.”
However, Kreps doesn’t believe the main tradeoff of The Lambda Architecture — maintaining a parallel code base for the batch and speed layers, which I briefly mentioned earlier — is worth it.
The problem with the Lambda Architecture is that maintaining code that needs to produce the same result in two complex distributed systems is exactly as painful as it seems like it would be. I don’t think this problem is fixable.
Kreps asks whether we might be able to re-envision our stream processing systems such that they can “improved to handle the full problem set in its target domain”. Namely, make it so that stream processors can be run in batch mode in order to address the reprocessing challenge. He claims to have had success with this technique at LinkedIn, and it eliminated the need to maintain parallel codebases.
In particular, he took advantage of the fact that Kafka can store historical data for long periods (e.g. 30 days, 60 days, even all time), and that LinkedIn runs Kafka clusters with petabytes of data available in the log. You can then use Kafka to “replay” this data against a parallel stream processor cluster whenever you need to do recomputation.
It’s an interesting suggestion, and one that I’m sure many practitioners in the field have thought about.
As a counter-point to this, I have lately thought about how the key aspect of batch systems is that they deal with “data at rest”, rather than “data in motion”. Because the data is at rest, you can express computations over that data in a much more functional way. This becomes especially important when the data you are trying to analyze and process has a time series feel — e.g. it’s always conceptually simpler to compute a “sum over all time” than to “pipe all time data through an incrementer stream.” Likewise, it’s easier to do a “distinct count over all data” rather than “maintain a unique set as new values arrive”.
In this way, I have a hope that a batch layer for a modern big data system could be much, much simpler than the speed layer, and could serve as an important check on the correctness of the speed layer. I think this is Marz’s point in Big Data, the book, as well.
That said, Kreps backs his argument up with good examples, so the full article is definitely worth a read.
Conclusion
A couple years ago, I predicted to my team at Parse.ly that stream processing would “go mainstream” in the open source community within a couple of years, and I think that prediction has turned out to be correct.
In a lot of ways, distributed stream processing is the natural next step for systems that have focused on parallelizing batch jobs across hundreds or thousands of commodity machines. It is also a natural area of interest due to the rise of large sensor and web data sets that tend to be streaming in nature.
The reason I’m so excited about Storm — and I think you should be, too — is that, like Hadoop, it provides a “unified architecture” for running distributed computation across commodity machines without sacrificing latency.
This architecture is strong enough that it goes beyond being an interesting Java technology to actually being an important piece of architecture that can be relied upon by many programming languages and communities. That is why at Parse.ly, we’re developing streamparse — to contribute our part by making Storm dead simple to use by Python programmers, in the same way that mrjob made Hadoop Streaming easy-to-use for that community.
I believe that Storm is one of those technologies where, “if you don’t use Storm for your worker-and-queues system, you’ll be doomed to eventually re-invent it.” This is because it solves fundamental problems — modeling data processing as a computation graph; high-speed network communication between threads, processes, and nodes; message delivery guarantees and retry capabilities; tunable parallelism; built-in monitoring and logging; and much more.
Like Hadoop in the early days, Storm is still a little rough around the edges. It certainly requires some expertise to get going, but as this article discussed, there are now plenty of strong resources available online and to purchase.
I am confident that over time, the open source ecosystem will bring more and more developers into the fold, and, with a little luck, stream processing will become a natural and easily-deployable tool in every data engineer’s toolbox.
So, what are you waiting for? Join in and contribute!
Parse.ly is hiring! Interested in working on Storm, Kafka, Python, and web analytics data at scale? Check out our jobs page. Also check out our Parse.ly Code & Tech page for more information about our open source contributions and conference presentations.
Books referenced and reviewed: Big Data, Manning Press; Storm Applied, Manning Press; Storm Blueprints, Packt Pub. NOTE: The book links, when they linked to Amazon.com, included an affiliate tracking code.
Image Credits: Official Storm Logo from the Apache Storm Project; Lambda Architecture diagram from Jay Kreps post on “Questioning the Lambda Architecture”; Big Data and Storm Applied covers by Manning Press; Storm Blueprints cover by Packt Publishing; Unified / Central Log diagram by Jay Kreps post on “The Log”.