Content analytics made easy
Parse.ly makes working with data easy for newsrooms and marketers, giving them the insights they need to focus their content strategy and prove ROI.
Our customers get results
122%
organic search traffic

+75%
revenue growth

+400%
subscribers

+20%
conversions

The analytics everyone can use
Most analytics tools are complex and require extensive training. Parse.ly’s intuitive dashboard gives everyone access to deep insights about your content. Make everyone on your team “the data person.”

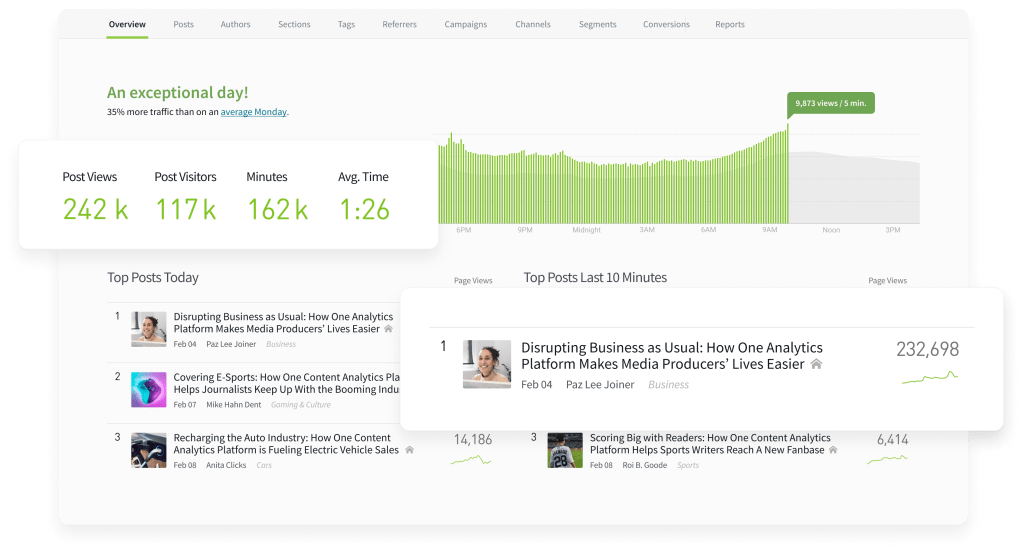
Analytics Dashboard
The accessible dashboard that everyone on your team can use to understand content performance.
- Real time data
- Conversions
- Reporting
Content API
The API you plug into your sites to serve recommended content that’s personalized to your audience and objectives.
- Customizable models
- Drag & drop WordPress block
- Aggregate data export
Data Pipeline
The pipeline you use to send raw event-level data from your website and apps to your data warehouse.
- Raw, real-time data
- Clean format
- Data storage

If you have an editorial team creating content daily that needs feedback on the performance of that content, then Parse.ly is the number one tool for the job.
Dan Stubbs
VP Analytics

Make Data Easy
Drive smarter decisions across the board by empowering creators with the tool they understand and love.

Focus Content Strategy
Identify what content resonates with your audience, and focus your work on high-value initiatives.

Prove Content ROI
Quickly prove what content drives business impact, and get management to invest in your team.

Parse.ly is the tool that makes it fun, simple, easy, and not scary to get data—you want to start using it on a daily basis.
David Grossman
We’ve seen real results: 25% for additive growth from our content marketing activities and objectives.
Chief Marketing Officer
Companies using Parse.ly every day










Ready to win more with your content?
Join thousands of editors and content marketers who use Parse.ly every day.